Recent text-to-image diffusion models have reached an unprecedented level in generating high-quality images. However, their exclusive reliance on textual prompts often falls short in precise control of image compositions.
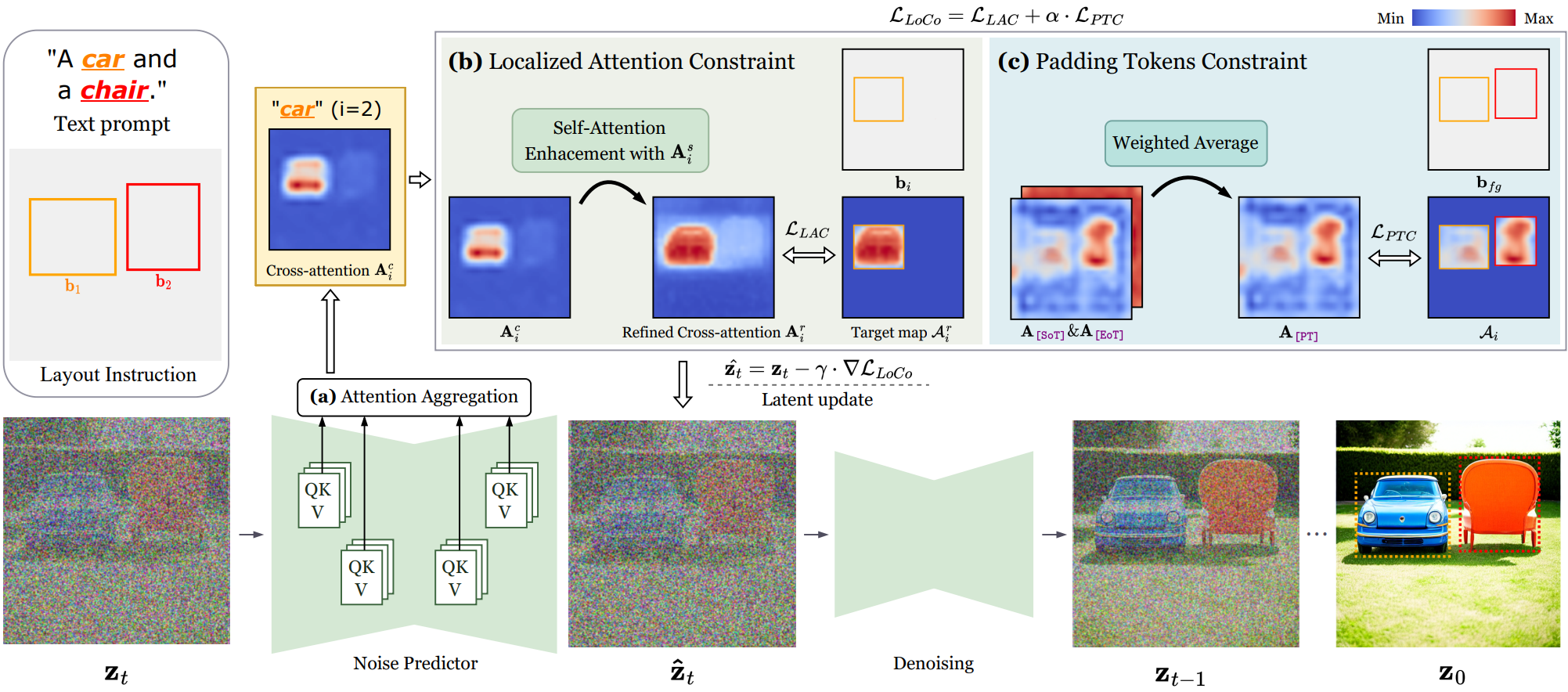
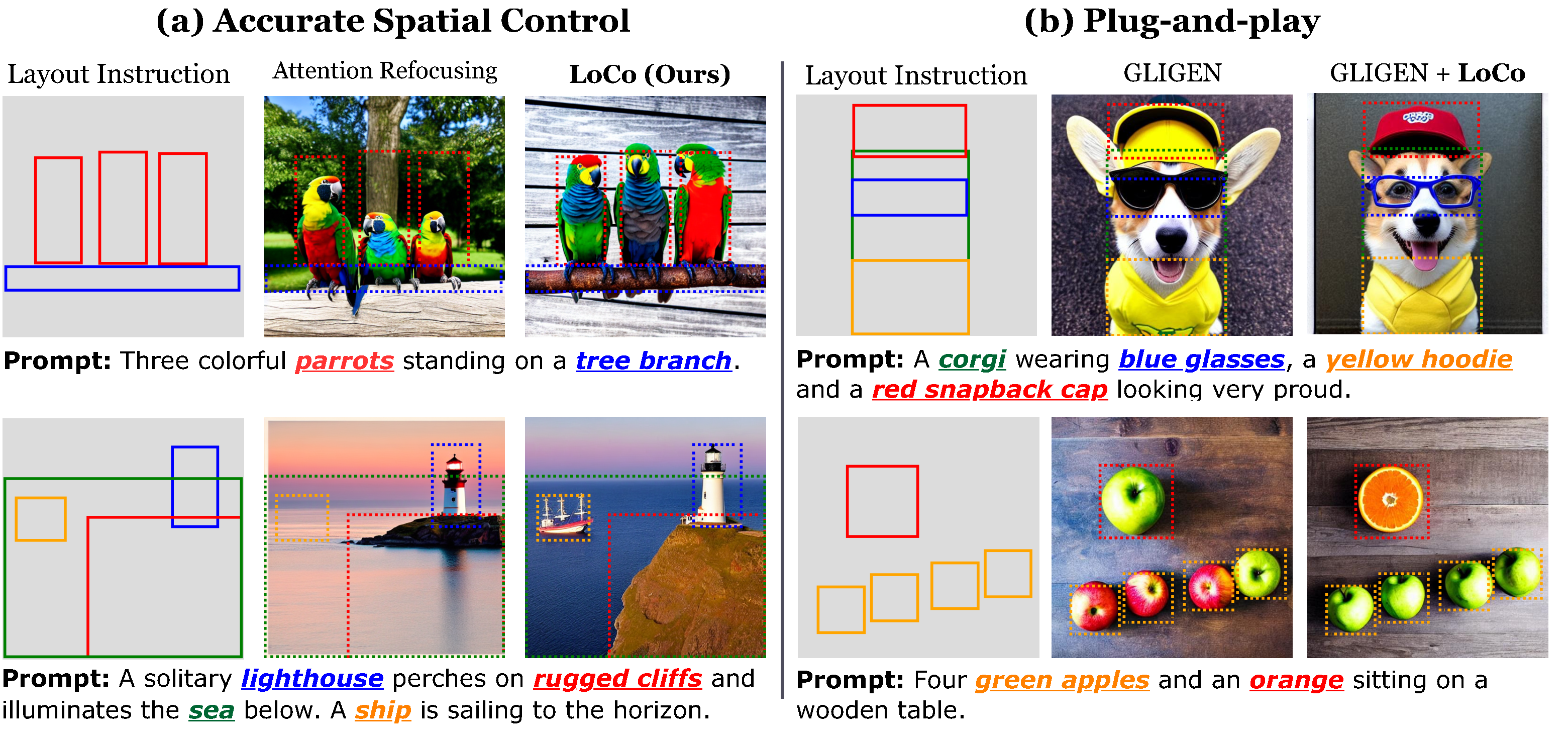
In this paper, we propose LoCo, a training-free approach for layout-to-image Synthesis that excels in producing highquality images aligned with both textual prompts and layout instructions. Specifically, we introduce a Localized Attention Constraint (LAC), leveraging semantic affinity between pixels in self-attention maps to create precise representations of desired objects and effectively ensure the accurate placement of objects in designated regions. We further propose a Padding Token Constraint (PTC) to leverage the semantic information embedded in previously neglected padding tokens, improving the consistency between object appearance and layout instructions.
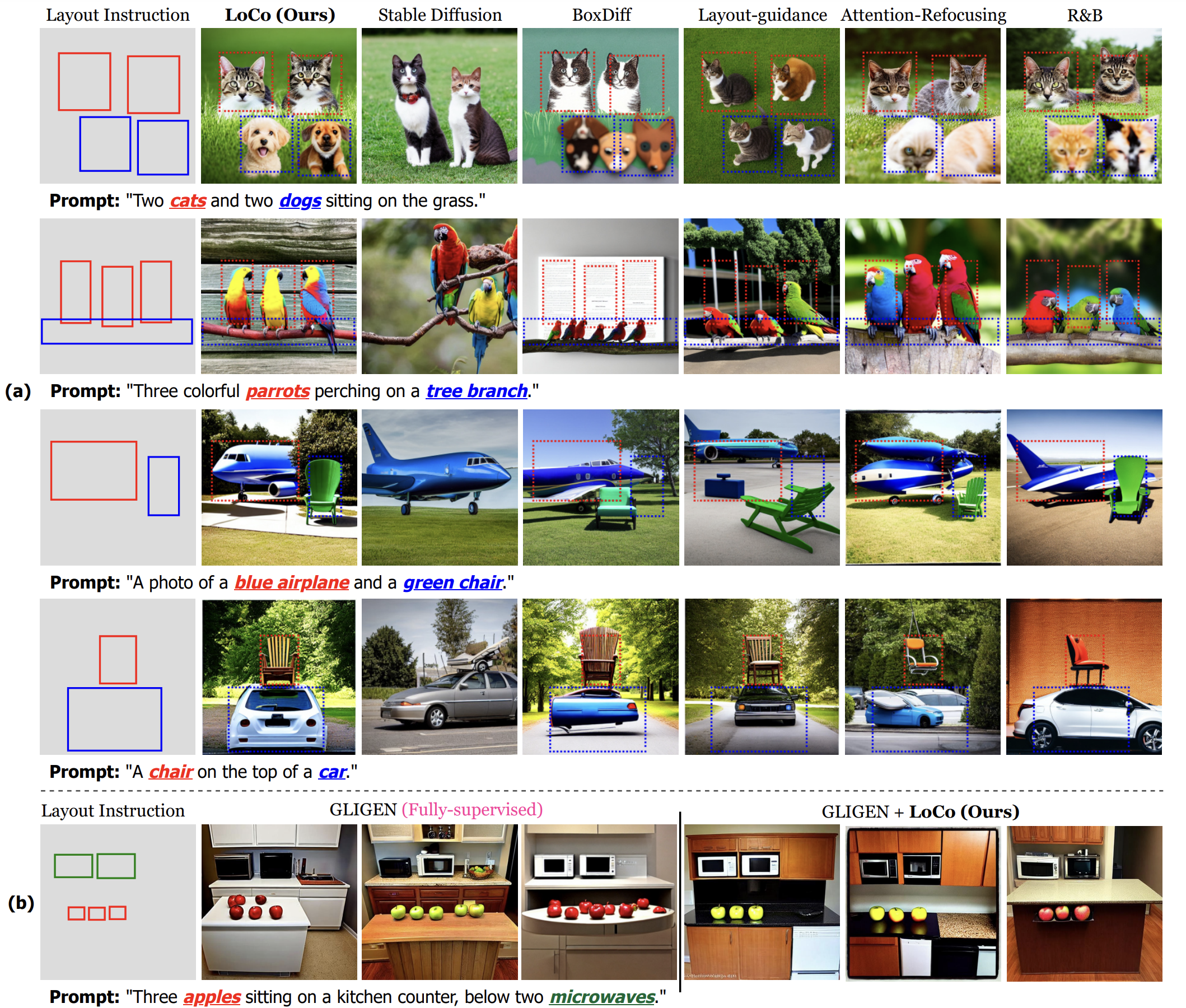
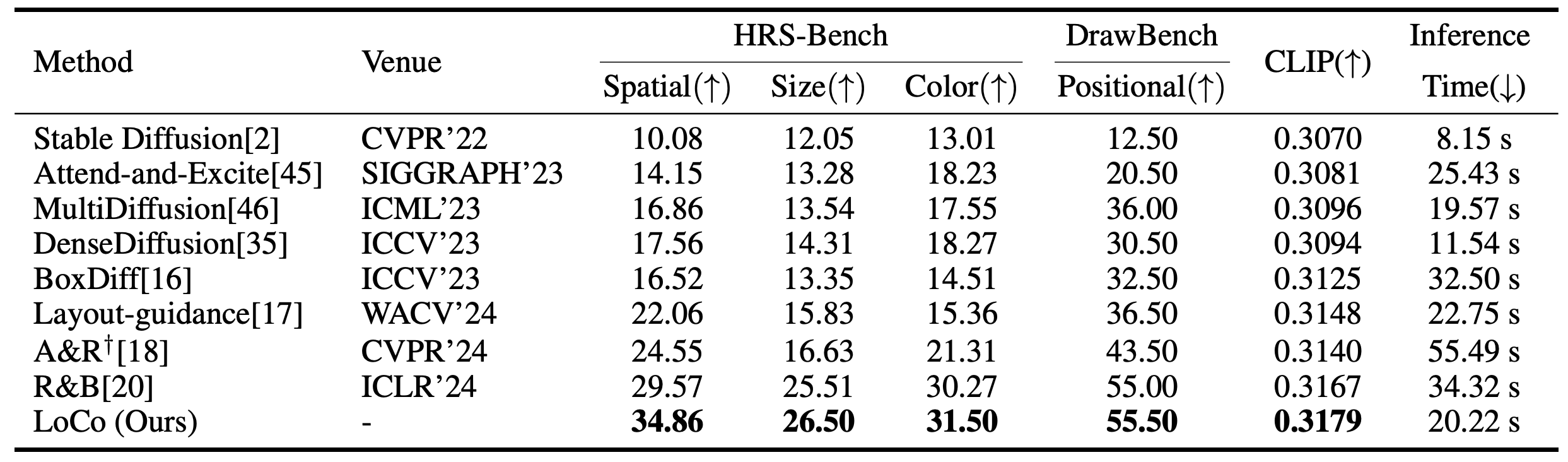
LoCo seamlessly integrates into existing text-to-image and layout-to-image models, significantly amplifying their performance and effectively addressing semantic failures observed in prior methods. Through extensive experiments, we showcase the superiority of our approach, surpassing existing state-ofthe-art training-free layout-to-image methods both qualitatively and quantitatively across multiple benchmarks.








@article{zhao2023loco,
title={LoCo: Locally Constrained Training-Free Layout-to-Image Synthesis},
author={Zhao, Peiang and Li, Han and Jin, Ruiyang and Zhou, S Kevin},
journal={arXiv preprint arXiv:2311.12342},
year={2023}
}